发布日期:2024-09-30 14:39 点击次数:77

OpenAIo1的发布日本女优大全,又一次激发了行业内对于大模子进化新范式的研究。
研究的焦点是两个公认的大模子进化瓶颈:数据瓶颈——数据不够用了;以及算力瓶颈——3.2万张卡已是刻下的天花板。
但o1模子似乎找到了新的出息,它领受强化学习,试图通过更深入的念念考和推理来克服这些收尾,提高数据质料和策画效力。
针对这一新范式是否能够鼓励大模子竞争参加新阶段,月之暗面创举东说念主杨植麟有一些新的深度念念考。
9月14日,杨植麟在天津大学宣怀学院作念了一场共享,腾讯科技作为媒体配结伴伴,第一时候对他的共享内容进行了梳理。
有关词,行业异日如何发展,无东说念主能精确揣度。于立异之途,更多时刻需要的是斗胆试错的风格以及不断直面失败的勇气。
杨植麟在共享的临了援用了《Thinking,FastandSlow》作家DanielKahneman(丹尼尔·卡尼曼)讲的话,他说:
“好多时候你自豪去作念一个你不知说念的东西,其实你不知说念有好多东西不知说念,是以你才有这样的勇气去作念。当你作念了,你会发现存好多新的问题,也许这个东西等于立异的意旨。”
以下为共享实录(有删减):
今上帝要共享一下对东说念主工智能行业发展的念念考。
东说念主工智能领域发展了七十多年,中间阅历了好多的发展阶段。2000~2020年,东说念主工智能主若是连合在垂直领域,比如说也出生了好多像东说念主脸识别、自动驾驶公司,其实这些公司中枢在作念的好多任务是垂直的任务,为了一个特定的任务来作念。
消耗东说念主力且是定制化的系统。这是之前AI中枢的范式,“种瓜得瓜,想吃一个西瓜就种西瓜,耐久不可种瓜得豆。”
这个范式在最近几年发生了很大的变化,不再是磨真金不怕火很特定的AI模子,而是磨真金不怕火通用的智能。
通用智能有什么刚正呢?并吞个模子不错用到不同业业、不同任务,不错极猛进度的泛化,是以它的空间会很大。
如果临了在好多领域作念到东说念主的水平,可能一定进度上对社会GDP产生杠杆,因为每个东说念主的出产力都会变大、变强。本来只可产生一份的出产力,关联词刻下用通用的AI帮你作念各式各类的任务之后,有可能能乘小数几倍,以致两倍、十倍,这个就取决于通用智能发展到什么阶段。
通用模子产生的三个身分
为什么最近几年一会儿能产生通用的模子?我以为它既是一个势必,亦然一个巧合。势必等于说东说念主类科技的发展老是有一天等于会达到这个节点。
关联词它的巧合是因为刚好霸道了三个身分:
第一,互联网发展了二十多年,为AI提供了大批的磨真金不怕火数据。互联网等于是把这个天下或东说念主的想法去作念数字化的经过,让每一个东说念主产生数据,每一个东说念主脑子里的想法最终造成了一堆数据。
这个很偶合,揣摸2000年的时候寰球开动作念互联网居品像搜索引擎的时候,或者作念流派网站的时候,可能从来莫甘愿想有一天这些数据尽然能够为东说念主类时髦的下一代科技产生孝敬。等于说在科技树的发展上,互联网是AI的前置节点。
第二,策画机内部好多时刻也都是AI的前置节点,比如说要达到10的25次方FLOPs(浮点数运算)的运算才能得到实足忠良的模子。
关联词要这样屡次浮点数运算同期在单一集群内部,在一个可控的时候范围内完成策画,这个在十年前是没法作念到的。
这就取决于芯少顷刻的发展、网罗时刻的发展,不光是芯片算得快,还要把芯片流通起来,还要有实足大的带宽、有实足大的存储,统共这些时刻叠在沿途才能在两三个月时候内算到10的25次方。
如果要花两三年才能算10的25次方,可能就磨真金不怕火不出来刻下的模子,因为重叠周期很长,每次磨真金不怕火失败了可能要再等好几年,就只可磨真金不怕火少一两个数目级的模子。关联词少一两个数目级的浮点数运算就产生不出来现存的智能,这个等于背后的所谓界限化定律决定的。
第三是算法上的栽种。Transformer结构是2017年被发明的,发明的开动照旧翻译模子,有点像专用的想法。其后有好多东说念主拓展更通用的想法,其后寰球发现Transformer是一个高度通用的架构。不管是什么样的数据,不管要学的是什么,只须能用数字化表述它就能用Transformer学习,而且这个通用体刻下界限化的性质尽头好。
如果用一个更传统的结构,比如说用轮回神经网罗或卷积神经网罗,可能会发现到了10亿参数或更多的时候,再加参数或再加策画就不会变好。关联词对Transformer来讲,只须一直加就会一直好,而且着实看不到上限。这样的结构,使得通用学习成为可能。只须不断地把数据放到模子内部去,然后界说你要学习的经营函数。
这三个东西加起来,就产生了刻下咱们看到的通用模子,而且是不可偏废。

咱们会发现很神奇,东说念主类时刻的发展都是站在前东说念主的肩膀上的。
有一册书是《时刻的实质》,尽头激烈保举!时刻的发展基本上是组合演进的经过,每一代的时刻不错认为都是前边好几代时刻的组合。关联词有一些组合能产生的威力会比剩下的组合要大得多,比如刚刚说的这三个组合就短长常刚劲的,它能产生通用模子。关联词在OpenAI之前,可能没东说念主能意想这三个东西组合起来尽然能产生这样大的威力。
AGI的三层挑战
在刚才这三个要素的前提下,我以为对于通用智能AGI来讲,可能会有三个层面:
最底层是界限化定律,这是第一个线索的立异契机,它被OpenAI发现,何况作念到极致。
第二个线索的立异契机,等于Scalinglaw框架下有一些问题莫得贬责日本女优大全,比如奈何把统共的模态用长入的暗示放到并吞个模子内部去?这是第二个线索的挑战。
同期,自然互联网发展了二十多年,但毕竟数据是有限的,合座累积的数据还不够多。刻下寰球碰到了一个问题,等于数据墙的问题,莫得更多的数据不错去磨真金不怕火了。
我举个例子,假定刻下要作念一个数学才气很好的AI,咱们应该想的问题是我应该有哪些数据会匡助我学习数学才气?现存被数字化的数学题是很少的,可能在互联网上有大部分数据又跟数学没什么谈论。
刻下好的数据被寰球用的差未几了,很难有任何一个东说念主或任何一个公司说,我今天不错找到比互联网大十倍的数据拿来磨真金不怕火,是以会碰到数据墙的问题。如果贬责第二线索的问题,就会获取第二个线索的契机,或者收益。
第三线索的问题,比如能够去作念更长的高低文,能够有更强的reasoning(推理)或者instruction-following(指示罢职),这些等于第三个线索的问题。

最底下的线索是第一性旨趣,有了第一性旨趣之后,是0和1的实质分辩。第一性旨趣之上,可能还有好多第二个线索,等于中枢时刻需要去贬责,刻下有好多东说念主在贬责第二个层面的中枢时刻,只须把第二个层面作念好也能让时刻从本来只是可行到变得尽头可用,而且是大界限使用。
如果看蒸汽机的发展都是一样的一开动发明了定理,发现第一性旨趣OK了。关联词蒸汽机落地经过中,一开动的能源不够好,或者是本钱太高,基本上统共新时刻出来都会有这两个问题,
刚刚咱们讲到有一个很热切的问题,等于数据墙的问题。在这种情况下,字据第一性旨趣,又要不断地磨真金不怕火更大的模子,要不断地加更多的数据,是以这内部就会有突破。
自然的数据依然被穷尽了,这个时候奈何能够加更多的数据?能够让它抓续作念界限化?这内部就会触及到范式的滚动。
蓝本作念的事情很节略,只是去揣度下一个Token,自己包含了尽头多的推理、常识。
比如假定刻下有一句话“距离北京最近的直辖市是天津”,讲话模子会把前边的东西作为输入去揣度临了的词是天津照旧重庆等等,它会作念揣度。揣度多了,就知说念是天津。通过这种揣度,就会把常识领受到模子内部,就能学会常识。
另外一种任务,比如刻下读了一册傍观演义,看了前边的九章,到临了一章要揣度凶犯是谁。如果能正确揣度凶犯,照旧像刚才说的作念下一个词的揣度。假定刻下有一句话,临了推理半天发现凶犯是某一个东说念主,其实这个模子就学会了推理。
如果有好多这样的数据,它就学会了推理。既能学到推理,也能学到常识,也能学到好多其它别的任务。如果把能搜到的数据全部拿下来,让它抓续揣度下一个词,它的技艺就会越来越高,推理才气会越来越强,常识会越来越多。
这内部会分红三种不同类型的能学到的东西:
第一,如果斟酌熵很低的情况下,可能一些事实性的东西、常识自己莫得任何熵,entropylevel尽头低,就径直把常识记下来了。
第二,推理经过,像傍观演义推理的经过有一个中等的熵,就可能有多条推理旅途,最终得到的是一样的收尾。
第三,比如说一些创作类的,刻下想写一个演义,它就不是一个敬佩性的事情,它的熵短长常高的。
这几种不同的东西都不错在一样的框架内部被揣度下一个词这样的单一经营,只作念这一件事情就能学会,这是通用智能的基础。把这些东西全部放在并吞个东西内部去学,而且无谓挑到底是在学小红书,照旧在学维基百科等等,是以它尽头通用,这个是通用智能的基础。
OpenAI发布o1,绚烂着新范式的产生
下一个范式是通过强化学习来作念。为什么要强化学习?等于因为刚才说的自然数据不够用了,最近OpenAI会发布o1,绚烂着从左边的范式移动到右边范式,因为左边范式数据不够了。就像刚才说的这个天下上数学题就这样多,如果要栽种数学奈何办呢?
不错一直生成更多的题,然后我方作念题,有的作念对了,有的作念错了,然后去学习哪些作念对了,哪些作念错了,你就不错抓续栽种,这个实质上等于强化学习的经过。
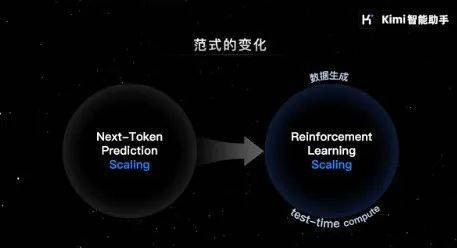
它的范式跟刚才说的又不太一样,刚才说的是找自然的数据去揣度下一个词是什么,刻下是通过第一步之后得到了一个比较好的基础模子,是以不错一直我方跟我方玩,生成好多数据,然后把好的学了,把不好的扔掉。通过这种形态去创造出来好多数据。
比如寰球如果去看o1的话,中间会生成好多的念念考。这个念念考到底有什么作用呢?中枢亦然生成数据的经过。因为这些数据自己辞天下上是不自然存在的,比如一个很历害的数学家讲授了一个新的定理,或者解了什么样的数学题,或者参加了什么竞赛解了数学题,只会把谜底写出来,不会把念念考的经过写出来,是以它是自然不存在这样的数据。
关联词刻下如果想让AI把东说念主脑内部自己的念念考经过给生成出来,然后通昔时学习这个念念考的经过,得到更好的泛化。比如刻下给一个学生一说念很难的题,如果径直去学这说念题的解答,其实并不知说念在干什么。其实他需要有东说念主给他讲一下,这一步蓝本是这样,为什么能得到这个念念路其实是有念念考的经过。如果能学到念念考的经过,下次碰到不太一样的题,他也能作念。
关联词如果只是学了解答的话,每一次只可作念一样的请示。只可说我今天解一个一元二次方程,每次都用一样的要津解,把这个题型背下来也不错。如果能学到念念考的经过,等于说有一个明师一直教你念念考的经过是什么样的,你把念念考的经过学下来,泛化才气会更好,而且能通过这个经过又产生了更多的自然不存在数据,它自己是很好的补充。产生了数据之后,这个Scaling就能抓续作念下去。
而且这个Scaling刻下也发生了一些变化,蓝本大部分Scaling发生在磨真金不怕火阶段,等于我找一堆数据让它磨真金不怕火。关联词刻下大部分的策画,或者说越来越多的策画会滚动到推理阶段,因为刻下要念念考,是以念念考的经过自己亦然需要花算力的,自己亦然不错被界限化的东西,等于能逐步往推理侧+更多的算力。这个也有利念念,比如今天想让一个东说念主去完成更复杂的任务,敬佩是需要花更万古候,不可能期待他一两秒钟就能讲授黎曼猜想。要讲授黎曼猜想,有可能要想好几年。
接下来很热切的点,怎么去界说越来越复杂的任务。在这些更复杂的任务内部,有可能模子跟东说念主交互的形态会发生一些变化,可能是从刻下实足同步的边幅,一定进度上造成异步的,等于允许它花一些时候查一些费力,然后念念考分析一下,临了再给你一个论述,而不是说飞速就给你一个解答。这样就能允许它完成一些更复杂的任务,等于把推理阶段的ScalingLaw跟强化学习衔尾起来。
这一代AI时刻的上限,中枢是文本模子才气的上限
我以为决定这一代AI时刻的上限,中枢照旧文本模子的才气上限,如果文本模子能抓续栽种技艺,等于能作念越来越复杂的任务。它有点像学习的经过,一开动能作念小学的题,逐步能作念中学、大学的,刻下有一些博士的常识和推理才气都具备。
文本模子在抓续栽种,这一代AI的上限就会很高。我以为文本模子是决定这一代AI时刻价值的上限,抓续栽种文本模子的才气很热切。自然刻下只须ScalingLaw能接续,大要率就能抓续栽种。
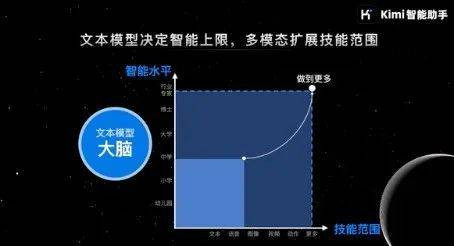
横坐标是加更多的模态,因为刻下寰球研究好多“多模态模子”。比如说会有视觉的输入、视觉的输出、音频的输入输出,会有这几个模态,以致在这几个模态内部大肆作念诊疗。比如今天通过一张丹青了居品的需求,这个居品的需求不错径直造成代码,这个代码内部还不错自动衔尾生成的视频作为LandingPage,这个任务等于横跨了多模态的任务,今天的AI还莫得主义实足作念到。可能一两年的时候就能把模态去衔尾起来。
最终这些模态衔尾多好是取决于大脑奈何样,等于文本模子实足强。因为中间需要很复杂的谋略,要谋略接下来先作念什么,作念第二步的时候发现收尾跟之前想的不太一样,不错随时调整,第三步不要这样作念了,不错换成别的形态作念。
这内部其实需要很强的念念考和谋略才气,需要在很长的窗口底下保抓一致、罢职指示、推理才气,这个其实都是由文本模子上限决定的。
关联词这两个东西是横向和纵向的,多模态的才气更多的是横向发展,等于能作念越来越多的事情。文本模子更多的是纵向的发展,决定了这个AI有多忠良。只须忠良了,AI才能作念好多事情。
关联词如果说很忠良,关联词莫得眼睛,那可能作念的事情也会受限,这是两个不同的维度。自然这两个维度在接下来也会同期得到栽种,在接下来两三年的时候内部我以为照旧有尽头大的概率,这两个方面应该会同步栽种,等于这样就能把通盘东西给包起来。如果把通盘东西包起来,等于所谓的AGI。
刚刚提到了一个问题,每一个新的时刻出来之后都会靠近两个问题:效力不太好、本钱太高。对于AI来说也一样,关联词好音讯是基本上这个效力的栽种还短长常惊东说念主的。最先会出刻下磨真金不怕火阶段,比如今天想磨真金不怕火一个GPT-4level的模子,花的磨真金不怕火本钱只是两年前的几分之一,以致如果作念得好有可能用1/10的本钱就能磨真金不怕火出来技艺一样的模子。
同期,推理本钱在抓续下落。本年比拟于客岁,在推理阶段产生单元智能的本钱基本上降了一个数目级,来岁揣摸还会再有一个数目级的下落。它会让AI贸易模子更开垦,获取智能本钱的会越来越低,但同期产生的智能越来越高。对于用户来讲,ROI就会越来越高,是以用AI的会越来越多,我以为这是一个很热切的趋势。

这两个热切的趋势重叠起来,一方面会在磨真金不怕火阶段得到越来越多的智能,另一方面是智能能越来越低廉的被东说念主使用,是以不错更大界限部署。自然这个模子还会抓续发展,我以为接下来如果去看OpenAIo1的话,很热切的栽种是刻下不错去完成一些比如东说念主类要想很久才能完成的任务,它不是在回报一个节略的问题,而是经过20秒钟的念念考。
自然这个20秒钟是因为策画机自己想的快小数,如果让东说念主想不异的内容,可能要想一两个小时。策画机不错把很久的经昔时作念一些压缩,能够去完成时长越来越长的任务,我以为这个是热切的趋势。
下一代模子的三个中枢才气
接下来你会看到也许AI能作念分钟级别以致小时级别的任务,同期会在不同的模态之间作念切换,推理才气也会越来越强。我以为这几个是接下来AI发展很热切的趋势。
咱们但愿能把居品和时刻去衔尾在沿途。刻下居品的逻辑跟互联网居品的逻辑发生了很大的变化。刻下的居品,基本上很猛进度上由模子才气决定的。如果模子才气作念不到,这个居品上的体验是莫得主义体现出来。
刻下有更多的想法,等于模子即居品。
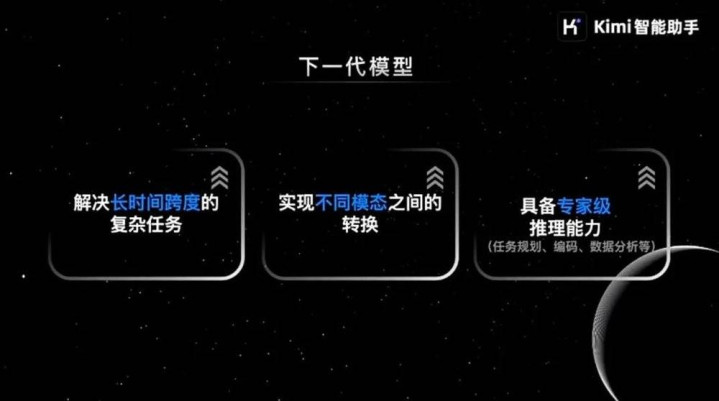
咱们在作念Kimi的时候,亦然很但愿能把居品和模子更笼统地衔尾在沿途去念念考。比如居品上想作念一个功能,背后是需要对应模子才气的解救。我以为这内部会有一个相对敬佩性的需求,AI的助理。我以为在AI期间,大要率超等诈欺就会是一个助理,我以为对智能的需求短长常普适的需求,只不外今天才气照旧处于低级阶段。同期,这个商场是顺应和拥抱新时刻的经过,其实是跟着效力不断变好、本钱不断下落,会导致有越来越强的商场顺应性。

我以为大要率接下来5到10年的时候内,敬佩会有大界限商场诈欺的契机。因为我以为它其实面向的照旧普适的智能需求。说白了,刻下用的统共的软件、APP背后是由几百、几千个工程师开垦出来的,是以背后的技艺是固定的。
关联词把东说念主的技艺通过一些代码(实质上是一种规定)编码下来,技艺就固定在那边了,它不会发生变化。
关联词对于AI居品来讲不太一样,因为背后是模子,不错认为模子等于有几百万个东说念主,而且几百万个东说念主的才气很强,不错帮你完成不同的任务,我以为它的上限是很高的。
这内部很热切的一件事是,如果想作念越来越复杂的任务,就必须能够支抓越来越长的高低文。是以咱们前期在这上头聚焦作念了好多才气上的栽种,通过高低文长度去贬责推理才气的问题。异日咱们也鸠合焦好多出产力的场景。

我以为这一代AI最大的变量,照旧在出产力端。刻下社会内部每一单元的出产力可能都会有十倍栽种的契机,是以咱们但愿能够聚焦在这些出产力场景,抓续把效力去优化得更好。自然效力优化得更好,背后对应的是模子才气的栽种。
同期,我以为AI刻下最大的变量是在于把数据自己当成变量来看,当你去优化一个系统的时候,数据不应该是手脚是常量,等于不应该是静止的东西,这个跟以前作念AI研究的范式也不太一样。比如如果是七年前或五年前,以致刻下好多东说念主研究AI时刻的要津是把数据固定,一个固定数据集,然后就去研究各式不同的要津、不同的神经网罗结构、优化器,就只是在固定数据的情况下去栽种效力。
我以为刻下数据越来越多会成为一个变量,等于奈何去使用数据,或者说获取用户的响应,其实会越来越多成为这内部很热切的东西。比如有一个很热切的时刻是RLHF(ReinforcementLearningfromHumanFeedback),中枢是奈何从东说念主类的响应内部去学习。即使说AI有很强的智能,关联词它莫得跟东说念主类的价值不雅对皆,或者产生的并不是东说念主类想要的东西,可能也不会有尽头好的用户体验。
我以为通往AGI的经过更多是共创的经过,不是纯时刻,应该是时刻跟居品更好的和会。就等于说把居品当成一个环境,然后模子就在这个环境内部跟用户交互,然后不断地从跟用户交互经过中去学习,这样就会抓续变得更好。
昔时从2018年开动,其时Transformer开动出来之后,咱们也作念了好多基于Transformer的研究和探索。自然一开动的时候,照实莫甘愿想最终效力能作念到今天这样。自然接下来效力还会抓续栽种,因为只须ScalingLaw一直存在,或者一直是开垦的,那模子技艺就会一直高潮。
经典三级电影
对我而言,通盘探索经过是宏大的,它源自于深入的敬爱心。在这个经过中,不敬佩性无处不在。有关词,咱们频频会比执行情况愈加乐不雅,这是因为咱们并不知说念有些东西是咱们所不知说念的。比如,在咱们最先开动这个式样时,自然意料到了许多繁难,但最终发现,不管咱们揣度了些许挑战,执行情况老是比咱们设想的愈加笨重。
尽管第一性旨趣可能了了明了,但未知的身分太多。正如《念念考,快与慢》的作家丹尼尔·卡尼曼所言,好多时候,咱们自豪去尝试那些咱们不知说念的事情,恰是因为咱们不知说念我方还有好多不知说念的东西,这种无知赋予了咱们勇气。当你开动尝试时,你会发现许多新问题,而这也许恰是立异的精髓方位。
可能大多数时候,你的尝试可能会失败,但偶尔你会发现某个贬责决策一会儿见效。这种情况频繁在咱们办公室发生,你会看到有东说念主一会儿雀跃,你可能会以为他出了什么问题,但执行上,他只是一会儿发现某个要津灵验了,就这样节略。
我认为,好多时候,不雅察哪些要津灵验,哪些无效,等于探索真义的节略经过。这种探索不单是局限于时刻领域,不管是居品照旧贸易模式,找出哪些可行,哪些不可行,或者只是是探索谜底自己,都短长常有价值的。
*感谢天津大学宣怀学院对本文的孝敬日本女优大全